OmniMon: Re-architecting Network Telemetry with Resource Efficiency and Full Accuracy
SIGCOMM ’20
总结:
提出了一个兼顾资源效率和完全准确度的分布式遥测架构;
摘要
对于管理员来说,以全网络范围的方式监控海量数据流量离不开网络遥测。现存的遥测方案经常面临:resource efficiency(即:低 CPU、内存和带宽开销)和full accuracy(即:无误差和整体测量error-free and holistic measurement)两者之间平衡的困境。
我们通过设计一个全网络范围的架构:OmniMon打破了这个困境。OmniMon可以在大规模数据中心的流级(flow-level)遥测同时实现resource efficiency and full accuracy。OmniMon精心协调整个网络中不同类型实体之间的协作,以执行遥测操作,从而在不影响完全准确性的前提下,满足每个实体的资源约束。它还提到全网时代同步的一致性和无误丢包推理的责任问题。(consistency in network-wideepoch synchronization and accountability* in error-free packet loss inference)
我们在DPDK和P4中制作了OmniMon原型。在商用服务器和Tofino交换机上进行的实验证明了OmniMon的有效性超过了最先进的遥测设计。
CCS CONCEPTS
• Networks → Network measurement.
KEYWORDS
Network measurement; Distributed systems
1. INTRODUCTION
背景:
现代数据中心承载着许多关键应用程序,从而对网络管理提出了很高的要求。管理员需要高效的网络遥测解决方案来监控海量流量并了解其全网行为。理想情况下,我们在开发网络遥测时,既要追求资源效率,又要追求准确性(resource efficiency and full accuracy)。
为了提高资源效率,网络实体(例如:终端主机和交换机)在计算、内存和带宽方面面临各种各样的资源约束。所以,遥测系统应该限制其性能开销,永远不要耗尽任何特定资源。尤其是网络遥测的性能开销必须远低于路由、NAT和防火墙中的普通数据包处理。需要注意的是,实现资源效率并不意味着随着网络规模的增长,资源使用量保持不变,相反,这里的资源效率目标是使网络遥测的资源开销远低于其他网络操作的资源开销。
为了达到完全的准确性,遥测系统应该具有网络内的、始终在线的可视性,覆盖所有流量和所有实体,并提供无差错的流量级统计数据。
传统的想法将资源效率和完全准确视为一种设计权衡。在一个极端,按流监控(如Trumpet[49]和Cisco Tetration[15])的目的是进行细粒度、无差错的测量,但可能会产生无限制的资源使用(保证完全准确,不保证资源使用限制);在另一个极端,粗粒度监控(如SNMP[12]、sFlow[64]和NetFlow[53])提供了尽最大努力的测量,但不保证准确性(保证资源使用限制,不保证完全准确,只是尽最大努力测量)。在这两个极端之间,许多遥测系统采用了近似算法[5,26,28,29,38,48,62,63,65,72,75],以实现具备可证明有界误差的资源高效率利用方案,或者实现只关注感兴趣的流量的事件匹配技术[25,33,52,69,74,79]。
提出问题:能否打破网络遥测中资源效率与全精度的困境?
我们提出一个基本问题:能否打破网络遥测中资源效率与全精度的困境?我们观察到,在不同的网络实体之间,包括数据平面的终端主机和交换机以及控制平面的集中控制器,在资源可用性和网络内可见性之间存在微妙的设计权衡 (§2.1)。通过仔细重新构建网络实体之间的协作,在其资源约束的前提下,我们可以设计一种新的遥测架构,实现资源效率和完全的准确性。请注意,最近的遥测建议也采取了协作的方法[24,52,67]。然而,它们解决的是不同的设计目标(例如,expressiveness表现力[24,52]或 in-network visibility网络内可见性[67]),而不是资源-准确度( resource-accuracy)的权衡。由于交换机资源紧张,它们的架构不能轻易实现完全的准确性(§2.2)。我们通过一个互补的协作遥测架构来填补这一空白,该架构将资源效率和完全准确度都视为’’一等公民(first-class citizens ) ‘’。
本文贡献:
我们提出了OmniMon,这是一种新型的全网架构,它可以仔细协调所有实体(即终端主机、交换机和控制器)之间的遥测操作,主要目标是同时实现大规模数据中心的流级网络遥测的资源效率和完全准确。具体来说,OmniMon以分割-合并的方式重新构建网络遥测架构。通过分割,OmniMon将网络遥测分解为部分操作(partial operations),并在不同实体之间调度这些部分操作。这种设计充分利用了整个网络的可用资源,避开了各个实体的资源限制。通过合并,OmniMon协调所有实体协同执行部分操作。它结合了终端主机和交换机(在数据平面)的优势,在整个网络中实现针对每个流的无错误的跟踪;同时,它的控制器(在控制平面)对所有终端主机和交换机进行全网资源管理和集体分析。请注意,OmniMon可在整个网络中的终端主机和交换机子集上逐步部署(incrementally deployable)。
(此处的思想可以结合SPEED)
就像任何实际的分布式系统一样,OmniMon 的全网架构设计需要解决网络遥测的可靠性问题(reliability concerns)。因此,OmniMon融合了一致性和责任性(consistency and accountability)这两个可靠性保证,在实际部署中既能保持资源效率,又能保证完全的准确性。
在一致性(consistency)方面,我们提出了一个混合一致性模型的全网纪元同步机制(epoch synchronization mechanism),如: (i)所有的实体在大多数时间都居住在同一个epoch,它们的epoch边界只存在很小的时间差(最多只能达到60𝜇s;see §8); (ii)每一个数据包在传输过程中,即使是在跨epoch网络延迟的情况下,在同一epoch也是同步的。
在责任性方面(accountability),我们规划了一个线性方程系统,用于每台交换机、每个流量的丢包推理,并通过考虑数据中心网络特性,确保在普通情况下存在唯一的解决方案。
实验及结论:
我们在DPDK[16]和P4[56]中实现了OmniMon的原型。我们还将OmniMon与Sonata[24]集成,以支持基本的查询驱动的遥测任务。我们在商用服务器和Barefoot Tofino交换机[70]组成的测试平台进行实验,也进行了大规模的模拟,证明了OmniMon比11种最先进的遥测设计更有效。例如,在P4交换机部署中,与基于sketch的解决方案相比(并不是零错误),OmniMon减少了33-96%的内存使用量,减少了66-90%的操作次数,同时实现了零错误[29,38,43,72]。
我们的Omni Mon原型的源代码现在可用:OmniMon。
2. BACKGROUND AND MOTIVATION
我们首先提出网络遥测中的资源和精度要求,并确定用例(§2.1)。然后,我们讨论了现有遥测系统中资源与准确度折衷的根本原因(第2.2节)。
2.1 Resource and Accuracy Requirements
我们专注于数据中心网络中的流量级网络遥测,在这个网络中,我们通过由数据包字段(例如,5-tuples)组合形成的流量密钥(flowkey)识别一个流量。我们以数值的形式,在被称为 “epochs”的固定长度的时间间隔内,测量流量级的统计数据。我们用整数来表示一个epochs,用当前时间戳除以epochs长度。 特别是,我们解决了网络遥测中的两个要求:资源效率和完全准确(resource efficiency and full accuracy)。
Resource efficiency:我们的目标是数据中心规模的网络遥测框架,包括三种类型的实体:多个终端主机、多个交换机和一个集中式控制器。每种类型的实体都有不同的资源限制。因此,框架应满足相应实体的资源约束,以保持整体的包转发性能。同时,它应该只利用商用硬件的现有功能。我们对每一类实体的阐述如下。
(i) End-host:终端主机在软件中(如内核空间[41]和用户空间[16])处理网络边缘的网络流量。它们为整体流量跟踪提供了充足的内存空间,并为实现各种遥测方法提供了高度的灵活性。然而,由于终端主机位于网络的边缘,它们对全网测量的网络内部的可视性较差。另外,商品主机上的软件数据包处理的计算成本很高(如需要多个CPU核才能达到40Gbps的速率[17]),然而终端主机不可能将所有的CPU资源只用于网络遥测,因为CPU资源也被其他协同应用共享。
(ii) Switch:商品交换ASIC实现了高转发吞吐量(如:Tbps级别[10,70])和超低处理延迟(如:亚微秒 sub-microseconds)。然而,它们具有稀缺的片上存储器空间(例如,数十MB内存用于保持状态[34,45]),并且由于过热问题和高制造成本,提供有限的可编程性。
(iii) Controller:控制器是一个逻辑实体,它集中协调所有终端主机和交换机,以获得全局网络视图。它可以由多个服务器组成,以便将它们的CPU和内存资源结合起来进行复杂的分析,并提供容错功能(例如,通过Zookeeper[30])。然而,它的网络带宽有限,无法接收所有终端主机和交换机的大量流量。
Full accuracy:我们将完全准确作为网络遥测的目标,这就意味着完整性和正确性(completeness and correctness)。所谓完整性,我们指的是跟踪所有实体和epochs的所有流量,不遗漏任何信息。所谓正确性,是指无误地跟踪每一个流的flowkey和完整值(complete values)。对于许多遥测任务来说,完全准确是非常重要的。我们展示了三个从full accuracy中大大受益的用例。请注意,现有的遥测系统也支持这样的用例(如[4,24]),但在实际部署中,任何测量误差都会降低其效率和可用性。
(i):Performance evaluation:管理员经常会提出新的技术来提高网络性能,并在实际部署中验证其正确性和性能增益。一个例子是评估基于flowlet的负载均衡(flowlet-based load balancing)[3]相比于比传统的基于流量的负载均衡(flow-based load balancing)的优势。管理员可以使用完整的每条流量轨迹进行细化,该轨迹揭示了每条链路的利用率和每个链路中的顶级流量。每条流完全准确的轨迹避免了测量变化或有错误的改进(flawed refinements),因此允许管理员专注于评估所提出的技术,而不必担心任何测量误差。
(ii):Anomaly detection:为了维护网络的可靠性和安全性,管理员需要识别网络异常(例如,行为不当或攻击misbehaviors or attacks)。 这种异常现象在实际发生之前很难预测。 因此,管理员需要对所有流量的每个epoch进行统计,以应对任何检测到的异常情况。每个epoch完全准确的统计消除了由于任何测量误差而导致的 错误警报或未检测到的异常情况,从而防止任何异常情况损害网络健壮性。在这里,我们专注于收集准确的流量统计,而提供精确的异常定义和配置则超出了我们的范围。
(iii) Network diagnosis( 网络诊断):在生产中,由于配置不当和硬件故障等各种原因,性能下降(如突发性高丢包)是常见的。管理员需要按每个交换机和流量的统计数据来定位和修复有问题的交换机和有损耗的流量。每台交换机、每个流量统计的完全准确意味着任何性能问题都能及时正确定位,而不会受到任何不准确测量的干扰。
2.2 Motivation
现有的遥测系统(§9)将资源效率和完全准确度作为一种设计权衡:它们要么提供足够的资源(即CPU、内存和带宽)来实现完全准确度,要么根据单个实体的资源限制牺牲完全准确度。(保证准确度就必须扩展资源,不扩展资源就之能放弃准确度)我们认为,这种权衡的存在有两个根本原因。
Root cause 1: Tight coupling between flow tracking and resource management.(流量跟踪与资源管理之间的紧密耦合)现存的方法是整体地实现遥测操作,其中终端主机或交换机提取每个观察到的流的值,并提供资源来跟踪这些值(由flowkeys引用)。为了解决流量之间的任何资源冲突,所提供的资源量必须足够大,然而这也在很大程度上取决于所需的准确度和各个实体的资源限制。
考虑一个例子,我们使用一个计数器的哈希表(例如,如Trumpet[49])来跟踪所有流量的flowkeys和值。为了解决哈希冲突,我们可以利用链式(chaining)或布谷鸟哈希[57]来组织碰撞流( colliding flows)的计数器。 这样的设计在软件中是可行的,但在交换机ASIC中却不能实现,因为由于交换机可编程性有限,很难实现哈希表的复杂内存管理。如果我们单纯地增加哈希表的大小,并依靠统一的哈希函数来解决交换机中的哈希碰撞,那么所需的计数器的数量将会非常大。图1(a)显示了不同哈希碰撞率下的内存使用情况(对于4字节的计数器)与流量数量的关系(一般来说,对于𝑚计数器和𝑛流量,碰撞率为$1-\frac{m !}{n ! m^{n}}$)即使是1000个流量,在1%的碰撞率下,内存的使用量也达到了200MB,这远远超出了交换机的容量。
现有的基于交换机的遥测系统为了将所有的操作融入交换机ASIC中,牺牲了精度[47,51]。一种解决方案是利用近似算法(如:sampling[62,63]、top-k counting[5,26,65]和sketch[28,29,38,43,48,75])来适应适应存储器中的紧凑结构。但是,由于提供的资源有限,不能保证完全的准确性(full accuracy)。另一种解决方案是将流量卸载到控制器上,以减轻交换机侧的资源占用[25,69,74,79],但它只监控感兴趣的流量,以避免压倒控制器的链路容量。
Root cause 2: Limited network-wide collaboration.(有限的全网协作)一些遥测设计采用了实体间协作的形式,但它们针对的是不同的设计目标,并仍然受制于资源与精度的权衡。例如,一些系统部署了一个控制器,用来收集来自终端主机或交换机[28,29,38,49]的测量结果和/或用来调整交换机之间的资源[43,47,48,62]。一些混合架构[24,52]允许交换机和控制器之间的协作,使遥测查询引擎更高效且富有表现力,而其他架构[32,42,67]则允许终端主机和交换机之间的协作,以结合终端主机的可编程性和交换机的可视性。然而,现有的协作方法并不能协调所有实体(即终端主机、交换机和控制器)之间的资源以实现完全的准确性。一些实体的资源有限,无法做到完全准确。
我们使用Sonata[24],一个协作的遥测架构,来激励我们的主张。sonata的目标是兼顾表现力和可伸缩性。它将数据流操作从控制器卸载到交换机上,以利用交换机快速处理数据包的能力。但是,它不能在不牺牲精度的前提下,减轻交换机端操作的内存和带宽占用。我们以开源的Sonata原型为例,使用[24]中报道的11个应用来评估其资源消耗。我们将改变每个应用的内存(范围是从128 KB到1,024 KB),并在Barefoot Tofino交换机上测量到控制器的总交换机流量[70]。我们比较两种情况: (i) ‘’精度下降’’,Sonata的原型中默认设置不处理哈希碰撞。 (ii)’’完全准确’’,在这种情况下,我们通过将每个流映射到𝑑(这里设置为2)个计数器来实现完全准确,如果一个流在所有的𝑑个计数器中都出现散列碰撞,则将该流放到控制器(参见[24]第3.1节)。我们在每个epoch都配置了$10^5$个活跃的流量(active flows)。图1(b)显示,在不同的应用内存下,accuracy degradation都会触发56 MB/s左右的流量。对于full accuracy的情况,由于哈希碰撞,触发的流量大幅增加(例如:在每个应用内存为128KB的情况下,是accuracy degradation的2.2倍)。请注意,处理哈希碰撞也会引起其他类型的交换机资源的过度使用(§8)。
3. OmniMon DESIGN
我们陈述我们的设计目标和假设(§3.1),并展示OmniMon如何实现资源效率和完全的准确性(§3.2)。我们提出了我们设计中的一致性和问责制问题( consistency and accountability)(§3.3)。
3.1 Design Overview
OmniMon是一种全网遥测架构,跨越数据中心网络中的不同实体(即终端主机、交换机和控制器)。它从架构的角度出发,通过重新架构所有实体之间受资源约束的协作,达到资源效率和完全准确的目的。它与现有的协作遥测设计兼容;作为案例研究,我们添加了一个基于Sonata[24]的查询引擎作为OmniMon上的应用,用于表达式遥测(§7)。由于不同类型的实体在资源可用性和网络内可见性上的不同,协调它们之间的协作是不简单的(non-trivial)(§2.1)。为此,我们从构建实用的分布式系统角度出发,解决了三个经典问题: (i)我们如何在不同实体(即终端主机、交换机和控制器)之间分配遥测操作? (ii)不同实体之间应该如何协调? (iii)面对不可靠的事件,我们应该如何实现可靠的协调?
Assumptions.我们做了几个设计假设:
- 我们关注的是单一管理域下的数据中心网络,这是现代数据中心的常见部署环境。管理员可以访问所有实体并对其进行配置。控制器对每个实体中的数据包处理策略(如路由表、访问控制列表和链路故障引起的路径变化)有充分的了解。
- 我们只考虑实际进入网络的数据包(即忽略终端主机中丢弃的数据包)。这可以通过在每个终端主机的网络堆栈的适当位置实现测量来实现(例如,Linux内核中的qdisc)。测量和剖析终端主机的网络栈不在我们的范围之内。
- 数据包格式是可扩展的。在传输过程中,数据包可以在现有的数据包头中的各种未使用的字段(如VXLAN中的保留位)中嵌入新的信息[3,20]。最近在用户空间网络堆栈[16]和可编程交换机ASIC[70]方面的进展也允许管理员随时定义自定义的数据包字段。需要注意的是,嵌入式信息的大小要小,以限制传输开销。
3.2 Split-and-Merge Telemetry
图2展示了OmniMon架构。回顾一下,OmniMon 遵循网络遥测的分割和合并方法(§1)。具体来说,它通过流键跟踪、值更新、流图和集体分析这四个部分操作(flowkey tracking, value updates, flow mapping, and collective analysis)来进行流转跟踪和资源管理。它在不同实体的异构资源需求的前提下,协调终端主机、交换机和控制器之间的这些部分操作。
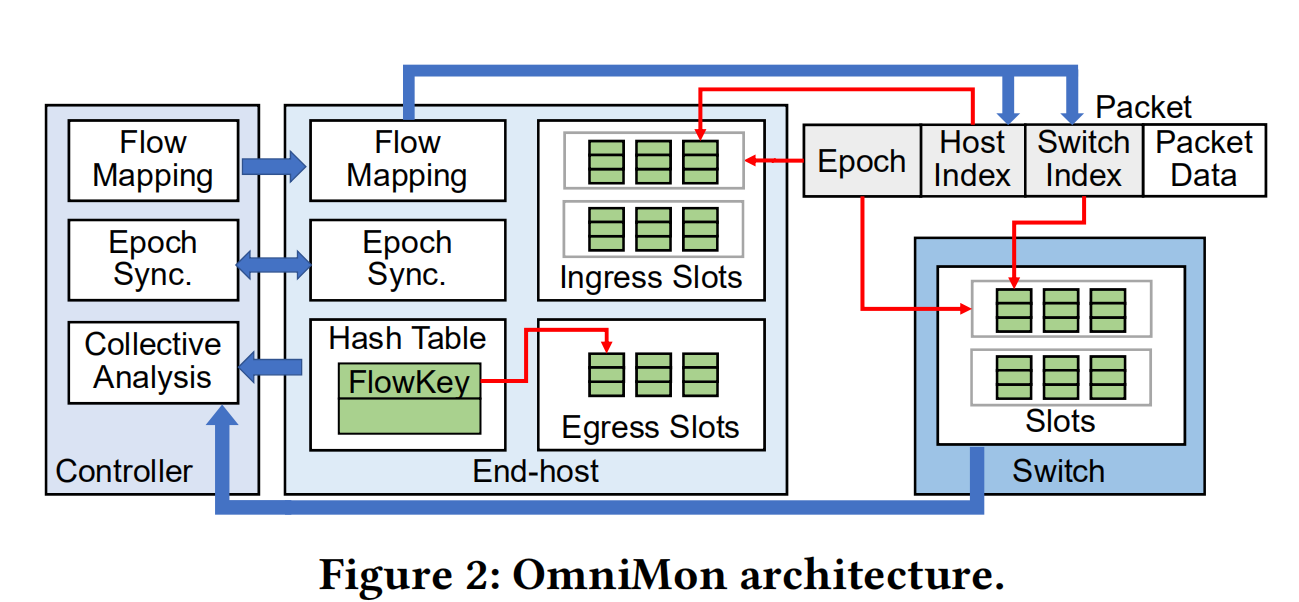
在下文中,我们将描述每一个局部操作,并展示如何同时实现资源效率和完全的准确性。我们首先假设有一个全局时钟,精确地同步所有实体,并且不存在丢包现象。我们以后会在§3.3中放宽这些假定。
Flowkey tracking(流键跟踪):OmniMon拥有网络中每个活动流的流密钥副本。当一个新流开始时,OmniMon会在源端主机中的哈希表中记录其flowkey。它在流终止时删除流密钥,这由TCP流中的FIN/RST数据包,或在较长的空闲时间(如30分钟[27])之后自动删除。
Value updates(更新值):OmniMon 在终端主机(具有充足的内存空间)和交换机(具有网络内可见性)中跟踪流量值。每个终端主机或交换机都维护着一组slots ,每个slots 有多个计数器,并进一步将slots 划分为不同epochs的组。由于终端主机和交换机对资源的要求不同,它们执行值更新的方式也不同。
在有足够的内存空间的情况下,终端主机每一个epoch为每个流动态分配一个专用slot。当一个流量终止时,它的slots将被回收。一个终端主机拥有两种类型的slots,即入口slots和出口slots。它将以自己为目的地的入站流量的值存储在入口slot(ingress slot)中,也将源自自己的出站流量的值存储在出口slot(egress slot)中。
另一方面,由于交换机的内存空间有限,我们允许一个slot由多个流共享。每个交换机将一个流映射到一个slots的子集,并通过流值更新所有这些slots中的计数器。因此,一个slot拥有多个流的汇总值。之后我们通过集体分析来恢复每个流量的值(见下文)。
Flow mapping.OmniMon协调所有终端主机和交换机将流量正确地映射到slots上,以进行流量键跟踪和值更新。其流量映射设计建立在带内数据包嵌入和带外消息的基础上。
(i)**Flow mapping in end-hosts.OmniMon 通过称为主机索引的索引号将流量映射到其在源端主机和目的端主机中的slot。当源端主机对一个新流应用流密钥跟踪时,首先计算主机索引,该索引表示流密钥在哈希表中的入口位置。然后,它将主机索引与流的出口slot关联起来,并将主机索引和epoch嵌入到流的每个传出数据包中。目的端主机从每个接收到的数据包中提取主机索引和epoch,并将它们与入口slot关联起来。使用主机索引消除了另一个哈希查找,这是终端主机的主要开销(§8中的Exp#1)。
(ii) Flow mapping in switches.OmniMon 为每个流量使用称为交换机索引的索引号,以确定流量如何映射到交换机中的多个slots。交换机索引由控制器和源端主机协同选择。具体来说,控制器为每一个可能的流量映射到交换机中的插slot分配一个唯一的交换机索引。然后,它为每个终端主机预先分配一个不相干的交换机索引子集。源端主机为一个新流选择一个交换机索引(详见§5.2),并将交换机索引(连同主机索引和epoch)嵌入流的每个传出数据包中。当交换机收到一个数据包时,会从数据包中检索出交换机索引和epoch,并更新相应的映射slot。这样的协作方式不仅可以利用控制器的可见性来缓解开交换机slot中的哈希冲突,还可以让源端主机在不查询控制器的情况下快速选择交换机slots。
Collective analysis.对于每个epoch,控制器从所有终端主机和交换机收集哈希表(流密钥)和slots(值)。它进行集体分析,将每个流量与它的源端主机和目的端主机以及流量所经过的每个交换机中记录的值联系起来,从而从每个端主机和交换机中恢复每个流量的值。由于OmniMon将所有流键保存在其源端主机中,控制器可以直接从源端主机和目的端主机中的专用slots中获取每流值(通过主机索引)。交换机中的每个流量值也可以根据终端主机中的流键(flowkeys)和值(values)从共享slots中恢复。具体来说,控制器知道所有映射到共享slot的流(通过交换机索引)。如果没有丢包,slot中的值就是映射到slot中的流的集合(例如:对于加法值,slot中的值等于每流值的总和);否则,在有丢包的情况下,OmniMon通过丢包推理恢复每个流的值(§5)。
Summary.OmniMon既能实现资源效率,又能实现完全的准确性。为了达到完全的准确性,控制器在每个epoch的基础上精确地恢复所有终端主机和交换机中的每个流的值(即同时解决正确性和完整性)。OmniMon通过三个方面来解决资源效率问题: (i)针对内存储,它只在终端主机中维护流量键和专用的每个流量的值,而在交换机的共享slot中只保留流量值;(ii)针对计算,它在控制器和所有终端主机中协同执行流量映射操作,而不涉及交换机,同时产生有限的开销(§8中的Exp#1和Exp#7); (iii)针对带宽,控制器收集哈希表和slots,而不是镜像所有流量。
请注意,与其他网络功能相比,这种资源使用量是微不足道的。对于终端主机来说,如之前的工作[28,49]所示,每个包哈希运算是可以承受的;相比之下,操作系统内核或虚拟化框架中的网络堆栈执行的每个包处理要比OmniMon中的每个包哈希运算复杂得多。对于交换机来说,OmniMon的部分操作所产生的资源使用量要比独立的遥测解决方案少得多,正如我们的评估(§8)所示。
3.3 Consistency and Accountability
OmniMon在其全网架构设计中面临两个不可靠的问题: (i)缺少全局时钟;(ii)包丢失。我们对OmniMon进行了一致性和责任保证的扩展,以便在面对不可靠事件时,既能保持资源效率,又能保持完全的准确性。
- Consistency:
- Accountability:
4. CONSISTENCY(一致性)
OmniMon通过全网的epoch同步实现一致性,目标是在同一epoch同步所有实体,并在同一epoch监控每个数据包的传输。我们陈述了在OmniMon中实现一致性的挑战(§4.1),并提出了一个新的一致性模型,该模型与我们的目标非常吻合,但又能可行地实现(§4.2)。
4.1 Challenge
虽然一致性在分布式计算研究中已经得到了很好的研究,但为网络遥测提供既能提高资源效率又能保证完全准确的一致性保证仍未被探索。现有的一致性协议主要针对强一致性或弱一致性(strong consistency or weak consistency)。我们通过图3中的例子来论证为什么在我们的上下文中,其中两个实体(终端主机或交换机)𝑒1和𝑒2交换数据包难以实现。
Strong consistency.(强一致性)强一致性对准epoch边界(Strong consistency aligns epoch boundaries),确保每个数据包在同一时代被所有实体观察到。例如,在图3(a)中,𝑒1和𝑒2均在epoch1处看到包A,在epoch2处看到包B。 然而,强一致性协议(如Paxos[37])在交换机中实现起来很复杂,而且会触发多轮带外消息进行同步。
Weak consistency.(弱一致性)弱一致性以尽最大努力的方式同步每个数据包的epoch,所以实体之间的epoch可能会有偏差,一个数据包可能会在不同的epoch被监控。在弱一致性中,每个实体通过本地时钟更新它的时序,并将当前的时序嵌入到每个发出的数据包中(如Lamport Clock[36]和Distributed Snapshots[13,73])。当一个实体收到一个数据包时,如果数据包的内嵌时间较新,它就会用数据包的内嵌时间更新它的当前时间。否则,实体会在转发前用当前的epoch更新数据包的嵌入epoch。
这种带内同步所产生的成本有限。然而,实体可能会在不同的epoch观察一个数据包,因为嵌入的epoch可以沿着数据包传输路径进行修改。 另外,一个严重时钟延迟的实体永远不会更新它的epoch,直到它收到一个具有较新epoch的数据包,造成epoch边界之间无限制的偏差(unbounded deviations)。例如,在图3(b)中,𝑒1和𝑒2都是通过带内数据包同步它们的时序(epochs)。然而,𝑒1的本地时钟被延迟,并保持在Epoch1,直到它收到来自𝑒2的数据包B。此外,𝑒1在包件A中嵌入了Epoch1,而𝑒2嵌入了Epoch2。因此,包A在其传输过程中可能被不同的实体不一致地处理为在Epoch 1或Epoch 2。
4.2 Hybrid Consistency(混合一致性)
OmniMon实现了混合一致性模型,在大多数时间内保证了强一致性,只在小的约束时间段内(如几十个𝜇s)降级为弱一致性。我们的想法是,OmniMon不仅在带内数据包中嵌入了时序信息(如弱一致性),而且还利用控制器的协调来实现全网时序同步。
Design overview.OmniMon在传输过程中为每个数据包决定一次时间。每个终端主机维护一个本地时钟,并决定其当前的epoch。当源端主机发送数据包时,会将其当前的epoch嵌入数据包中。路径上的所有交换机和目的端主机根据内嵌的epoch监控相应slots中的数据包。如果嵌入的epoch更新,目的端主机会进一步更新其当前epoch。请注意,交换机不维护本地的epochs以保持其处理流水的简单性。
当一个终端主机通过它的本地时钟更新它的epoch时,它将新的epoch发送给控制器,控制器通过带外消息将新的epoch转发给所有其他终端主机。因此,所有的终端主机都可以保持最新的epoch,即使它们的本地时钟被延迟或它们没有收到任何具有较新的嵌入epoch的数据包。通过这种控制器辅助的方法,从一个终端主机到另一个终端主机传播一个新的epoch最多只需要两跳。因此,任意两个终端主机的epoch更新之间的时间差大约是控制器和终端主机之间的路径延迟的两倍,在实践中大约是几十到几百微秒(例如,在我们的评估中,对于1024个终端主机来说,不到60 𝜇s),而且比epoch长度小得多(例如,几十或几百毫秒[38,49])。
控制器维护着它的本地epochs。它只在收到具有较新epoch的带外消息时才更新和重发epoch。我们可以证明,每个终端主机在每个epoch只触发𝑂(1)外带消息(见附录中的证明)。另外,带内流量的变化对一致性模型的影响有限(§8中的Exp#3)。
图4描述了混合一致性模型。在大多数情况下,所有终端主机(例如,图中的ℎ1和ℎ2)都驻留在同一个epoch。然而,终端主机有时仍可能驻留在不同的epoch(例如,当ℎ2收到C包时),在这种情况下,OmniMon只能确保弱一致性。尽管如此,弱一致性的持续时间受到控制器辅助同步的限制。另外,OmniMon还能确保每个数据包在路径上的同一时间点被监控,即使其源端主机和目的端主机尚未同步。例如,包C在Epoch 1由ℎ1发送,但在Epoch 2由ℎ2接收。然而,ℎ1和ℎ2都在Epoch 1(它的嵌入Epoch)监视包C。在附录中,我们正式证明了混合一致性的特性。
Algorithm.算法1显示了实现混合一致性的控制器和所有终端主机之间的epoch更新操作。 一个终端主机通过其本地时钟(第1-3行)、接收到的数据包的较新的一个内嵌epoch(第4-6行)或来自控制器的带外消息的较新epoch(第7-9行)来触发其epoch的更新。如果终端主机通过它的本地时钟触发了它的epoch更新,它也会将新的epoch发送到控制器。对于控制器来说,如果它从一个终端主机接收到一个较新的epoch,它就会更新它的本地epoch,并将其发送给所有其他终端主机(第10-14行)。
1 | Algorithm 1 Epoch updates in hybrid consistency |
Remark.(备注)算法1实质上是Lamport Clock(LC)的变种[36],但在两个方面与LC不同。首先,LC仅仅依靠数据包嵌入来进行时序(epoch)更新,而算法1则同时依靠数据包嵌入和控制器的带外消息来加快时序(epoch)更新。其次,LC涉及所有实体嵌入新的epoch进行值更新,而算法1通过控制器和所有终端主机确定epoch,但不是交换机。因此,LC只提供弱一致性,而算法1提供混合一致性。
Distributed controller.随着网络规模的扩大,OmniMon可以部署多个控制器实例,每个实例管理有限数量的终端主机。我们扩展了我们的epoch更新机制,使OmniMon能够在控制器实例之间同步epoch。具体来说,除了连接到终端主机的控制器实例(称为the leaf instances),我们还配置了一个与所有the leaf instances通信的控制器实例,称为the root instance。一旦任何叶子实例(the leaf instances)进入一个新的epoch(在收到来自其连接的终端主机之一的消息时),它就会通知根实例(the root instance),然后根实例(the root instance)会将这个新epoch广播给其他叶子实例(the leaf instances)。每个叶子实例也将epoch更新发送到其连接的端主机。这种两层机制最多需要四次跳(即叶子实例和终端主机之间需要两次跳,叶子实例和根实例之间又需要两次跳)来传播一个新的epoch。因此,任何两个终端主机的epoch更新之间的时间差仍然很小,而且是有界的。我们的评估(见第8节第4段)显示,一个控制器实例可以管理1024个终端主机,因此我们的两层epoch更新机制可以支持现代数据中心的规模。
5. ACCOUNTABILITY(问责制)
OmniMon通过在每个交换机、每个流量的基础上推断准确的流量损失来实现责任制,从而可以从每个交换机的共享slots中恢复每个流量值。我们的损失推理与经典的网络断层扫描(network tomography)[8,22]有关,然而后者由于网内可见性有限,往往只关注终端主机信息,目的是将精度损失降到最低。相比之下,我们的推理模型是全网的(覆盖所有终端主机和交换机),目标是完全准确。在这里,我们以加法流量值为目标,并在附录E中描述如何将非加法流量统计转换为加法值。
5.1 Problem
Motivating example.在不失通用性的前提下,我们把重点放在数据包数量上。我们将包丢失推理问题表述为求解一个线性方程系统(简称线性系统),其中变量代表单个的每台交换机、每个流量的包丢失。然而,线性系统可能有多个可行的解(即我们无法唯一地推断出准确的数据包损失)。我们考虑一个玩具的例子(toy example)(图5),促使问题的解决。假设有两个有损流量𝑓1和𝑓2,这两个流量都通过交换机𝑠1和𝑠2,并且在两个交换机中共用同一个slots。根据源端主机和目的端主机中的流量值,我们知道每个流量正好丢失一个数据包。但是,我们无法判断每个交换机中哪个流量的数据包被丢弃:要么𝑠1丢弃𝑓1的数据包,而𝑠2丢弃𝑓2的数据包;要么𝑠1丢弃𝑓2的数据包,而𝑠2丢弃𝑓1的数据包。
上面的例子显示了一种极端的情况,即即使只有两个有损失的流,也会使精确的丢包推断变得不可行。尽管如此,通过加入数据中心网络的特性,我们可以设计一种协同的流量映射算法(§5.2),将流量映射到不同的交换机slots。该算法简化了线性系统,避免了图5中的极端情况。它还返回了普通情况下每个交换机、每个流包损失的唯一解。
Formulation.(构想出,规划;确切地阐述;用公式表示)让 𝑛 是有损流的数量(𝑓1, - - , 𝑓𝑛), 𝑚是交换机的数量(𝑠1, - - , 𝑠𝑚)。让$k_t$是交换机$s_t$的slots数量,损耗流被映射到其中(1≤𝑡≤𝑚)。例如,图5中有𝑛 = 2,𝑚 = 2,𝑘1 = 1,𝑘2 = 1。我们将全网丢包推理问题表述为一个线性系统,如下。
Variables: 设$x_i$(1≤𝑖≤𝑚𝑛)为一个变量,量化每台交换机、每个流的丢包量(以丢包数为单位),这样$𝑥_1$~$𝑥_𝑛$分别为$𝑓_1$~$𝑓_𝑛$在$𝑠_1$的丢包量,$x_{n+1}$~$x_{2n}$分别为$𝑓_1$~$𝑓_𝑛$在$𝑠_2$的丢包量,以此类推。例如,在图5中,我们定义了四个变量:$𝑥_1$和$𝑥_2$分别是$𝑓_1$和$𝑓_2$在$𝑠_1$中的数据包损失,而$𝑥_3$和$𝑥_4$分别是$𝑓_1$和$𝑠_2$中的数据包损失。
Equations:我们制定两组方程。首先,每个slot都会引出一个映射到slot本身的有损流的方程(即:总共有$\sum_{t=1}^{m} k_{t}$方程)。例如,在图5中,$𝑠_1$中的slot催生(induces)$𝑥_1$+$𝑥_2$=1,而$𝑠_2$中的slot催生$𝑥_3$+$𝑥_4$=1。其次,每个流量根据源端主机和目的端主机中的流量值之差,产生其总丢包量的方程(即总共𝑛个方程)。例如,在图5中,$𝑓_1$引起$𝑥_1$+$𝑥_3$=1,而$𝑓_2$引起$𝑥_2$+$𝑥_4$=1。设$𝑀_𝑡$(1≤𝑡≤𝑚)是一个$𝑘_𝑡$×𝑛 0-1矩阵,该矩阵指定了在交换机$s_t$共享slots的𝑛个损失流的映射。如果流$𝑓_𝑗$(1≤𝑗≤𝑛)遍历$𝑠_𝑡$,并映射到$𝑠_𝑡$中的slot 𝑖(1≤𝑖≤$𝑘_𝑡$),$𝑀_𝑡(𝑖,𝑗)$则为一;否则为零。让 $I$ 是大小为 $𝑛$ 的单位矩阵(identity matrix),其中每一行表示沿 𝑚 个交换机的一个损耗流的丢包变量。我们将线性系统表示为$A \cdot \vec{x}=\vec{b}$(例如,见图5),其中𝐴是一个$\left(\sum_{t=1}^{m} k_{t}+n\right) \times m n$矩阵,由下列公式给出:
$\vec{x}$是一个大小为𝑚𝑛的列向量,包含所有$𝑥_i$,而$\vec{𝑏}$是一个大小为$\sum_{t=1}^{m} k_{t}+n$的列向量,由𝑚个交换机中所有 slots(共$\sum_{t=1}^{k} 𝑘_𝑡$) 的包损失(共$\sum_{t=1}^{m} 𝑘_t$包)以及𝑛个流的总包损失组成。我们的目标是求解给定$\vec{A}$和$\vec{b}$之后的$\vec{x}$。
Rank analysis.如果且仅当𝐴的秩等于变量数𝑚𝑛时,线性系统有唯一解。𝐴 的秩取决于 $𝑀_𝑡$ 和 $𝐼$。显然,$𝐼$的秩为$𝑛$。假设我们构造了一个大小为$(\sum_{t=1}^{m} k_t)×𝑛$的新矩阵𝑀,其中𝑀的行由每个$𝑀_𝑡$的所有行一起组成。让$𝑟$成为𝑀的秩。我们可以证明,𝐴的秩的紧上界(tight upper bound)是 𝑟(𝑚 -1) +𝑛 (附录)。因此,我们可以提出accountability的必要条件(即可以推断出确切的丢包量)。
如果𝑚=1,则accountability的条件始终成立;否则如果𝑚>1,则只有当𝑟=𝑛时才成立。请注意,𝑀的每一行都代表一个映射到交换机中一个slot上的流。这就在accountability和映射到slots上(𝑀指定的不同交换机中的)的流之间建立了联系,从而促使我们设计一种流映射算法来返回满足accountability条件的𝑀。
Challenge.遗憾的是,accountability条件一般不成立。例如,在图5中,由𝑀1和𝑀2构成的矩阵𝑀,其秩为𝑟=1,但却有𝑛=2个流量。一般来说,秩 $r \leq \min \left\{\sum_{t=1}^{m} k_{t}, n\right\}$。如果映射的slots数(即$\sum_{t=1}^{m} k_t,n$ )小于流量的数量(即𝑛 ),那么对于任何流量映射来说,不可避免地会出现 𝑟 < 𝑛 。
5.2 Collaborative Flow Mapping(协调流映射)
Observations.我们展示了我们如何利用数据中心网络的特性,使accountability条件在普通情况下成立。我们提出了两点意见,这些意见已经被最近关于生产数据中心的研究所证实[2,6,23,60,68,79]。
(i) Traffic locality. 现代数据中心表现出很强的流量位置性,即流量轨迹被限制在一个机架(rack)或集群内[6,60]。例如,在Facebook,大约85%的数据中心内部流量停留在一个集群内(参见[60]中的表3)。因此,一个有损流量往往只穿越几个交换机,$\vec{𝑥}$中的许多变量可以设置为零,以降低对𝐴的秩的要求(即小于𝑚𝑛)。
(ii) Loss sparsity.鉴于最近的拥塞控制机制[2]和故障缓解机制[23,68,79]极大地抑制了数据包丢失(packet losses),丢包(Packet drops )在数据中心网络中分布稀疏。这种损耗稀疏性(loss sparsity)意味着数据包损耗很可能正好发生在本地区域内(within a local region)的一个交换机(例如,一小组机架或集群)。换句话说,对于仅在一个区域内遍历的所有本地损耗流,它们的丢包(packet losses)都归于一个交换机。因此,我们可以推断出这种局部流(local flows)的 $\vec{𝑥}$ 中的变量(回忆一下,我们可以根据accountability condition,在𝑚=1的情况下为这种局部流解出唯一的解)。这就进一步放宽了对𝐴的秩要求。
Design.以上两个观察结果通过减少$\vec{𝑥}$中的变量数量,大大简化了线性系统。对于 $\vec{𝑥}$ 中的其余变量,我们的目标是通过流映射来构造一个具有最大秩𝑟的新矩阵𝑀,这样简化的线性系统可以返回一个具有高可能性(likelihood)的唯一解。然而,这个问题仍然是不简单的(non-trivial),因为有损流量是不可预知的,我们无法预先知道有损流量如何映射到不同的slots。这样的设计有两个好处。
OmniMon受到Bloom filters [7]的启发,通过将流量映射到每个交换机中的 𝑑>1 个slots来解决这个问题。首先,有损流映射的slots数增加,其期望值等于𝑛𝑑(附录)。其次,可能的流映射数量增加到$𝑂(𝐾^𝑑 $),其中$𝐾$是一个交换机中可用slots的总数,这样两个有损流(lossy flows)被映射到同一个$𝑑$ slots(the same 𝑑 slots)的可能性就降低了。因此,随着映射slots(即𝐴的行)数量的增加和重叠流映射(overlapped flow mappings)(即线性依赖 列)数量的减少,𝐴的秩会增加。例如,可以避免图5中的极端情况。
Omni Mon采用两阶段协作的方法来确保任何新的流被映射到不同的𝑑 slots集(a different set of 𝑑 slots)。在第一阶段,控制器生成所有$\left(\begin{array}{l}K \\d\end{array}\right)$可能的流映射,并在其启动过程中为所有终端主机划分流映射,从而使每个终端主机收到一个不同的流映射列表。在第二阶段,源端主机在看到新的流量时,会选择一个未分配的流量映射。并在流钥匙跟踪(flowkey tracking)期间,在流终止时回收任何分配的流映射(§3.2)。请注意,如果有太多的活动流(active flows),源端主机可能会用完未分配的流映射,在这种情况下,我们为新流选择最近使用最少的流映射。
Summary. OmniMon通过数据中心网络的特性来简化线性系统,以推断准确的数据包损失。我们将这些步骤总结如下。
- Step 1:识别源端主机和目的端主机的流量值之差为非零的任何有损流量。
- Step 2:构造$M_t$(and hence )A和$\vec{b}$。
- Step 3:细化$\vec{x}$中的变量。对于局部流量,如果流量不遍历交换机,我们将相应的变量设置为零。在损耗稀疏( loss sparsity)的情况下,我们检查每个局部区域(通过机架或集群)。 如果一个区域正好有一个交换机有丢包现象,我们就找出这个区域的所有本地流量,并求出这些本地流量对应变量的唯一解。
- Step 4:解$A \cdot \vec{x}=\vec{b}$以求得剩余变量。
6. DISCUSSION
我们讨论了OmniMon的一些实际部署问题。
Scalability. 随着网络规模的扩大,OmniMon需要更多的资源(如交换机中的内存、终端主机和控制器中的CPU功率等)来实现完全的准确性。但是,其完全准确所需的资源使用量的增长速度远远低于网络规模的增长速度。对于终端主机来说,由于流量是独立的,当一个CPU核无法处理所有流量时,OmniMon可以在不同的CPU核中处理流量。与网络堆栈的处理开销相比,它的资源效率仍然高得多,因为它的哈希计算和值更新在商品CPU中产生的开销很低[49]。对于交换机来说,由于$K$个slots提供$\left(\begin{array}{c}K \\d\end{array}\right)$流映射,当$𝑑>1$时,少量的$𝐾$增量可以处理更多的流。即使当流的真实数量超过$\left(\begin{array}{c}K \\d\end{array}\right)$(Exp#5 in §8),OmniMon仍然能保持其准确性。对于控制器,它是一个逻辑实体,可以支持多个物理服务器(§2.1)。此外,即使对于大量的终端主机(§4.2),它只转发有限的带外流量,并可以使具有多个CPU核[50,66]的线性系统加速求解。
Parameterization. OmniMon允许简单的参数配置。对于终端主机,我们可以根据需求调整资源。对于交换机,我们可以为不同的epoch重复使用slots。我们需要配置被跟踪的最大epoch数和每个epoch的slots数。追踪的epochs数是根据epoch长度和可容忍的网络延迟得出的,这两点是可以配置的。例如,如果我们使用长度为100毫秒的四个epoch,我们可以跟踪网络延迟高达400毫秒的数据包;任何延迟超过400毫秒的数据包都不会被监控。每一epoch的slots数取决于被跟踪的最大流数(§5.2)。回顾$𝐾$个slots意味着$\left(\begin{array}{l}K \\d\end{array}\right)$可能的流映射,如果我们将每个流映射到𝑑 slots。给定最大流数𝑛,我们选择𝐾和𝑑,这样$\left(\begin{array}{c}K \\d\end{array}\right) \geq n$。我们现在选择𝑑=2(较大的𝑑意味着交换机中更多的计算开销)。
Generality.OmniMon支持数据包字段的各种组合作为流密钥定义,以及不同类型的流统计(如[35,40,46,71]中的344统计)。然而,由于OmniMon的工作粒度是以epoch为单位的,它不能对数据包时间戳进行细粒度的集体分析。相反,它现在提供粗粒度的时间戳测量。例如,它通过跟踪流发生的第一个和最后一个epoch,以epoch数估计流完成时间。
Incremental deployment.OmniMon现在假定在终端主机和可编程交换机上进行全面部署。我们还可以在感兴趣的终端主机和交换机(如核心交换机)的子集上增量部署OmniMon,以进行部分测量(即只测量穿越部署设备的流量)。描述增量部署和完全准确之间的权衡是我们未来的工作。
Failure handling.Omni Mon需要在测量过程中处理不同类型实体的故障。对于终端主机,OmniMon会丢弃任何失败的终端主机的交换槽(switch slots),因为这些槽(slots)的流量映射是由控制器分配和知道的(§5.2)。恢复终端主机信息不在我们的范围内,然而可以通过操作系统级的容错机制来实现[9,18]。对于交换机,OmniMon通过损耗推理( loss inference)来定位交换机故障(附录中的Exp#8)。对于控制器,其容错性可以通过多个服务器实现(§2.1)。
7. IMPLEMENTATION
我们实现了OmniMon的原型。我们在附录中介绍了它所有操作的伪代码。
End-host.我们利用DPDK[16]来消除内核空间开销。我们使用mTCP[31]这个用户空间网络协议栈来实现终端主机和控制器之间的通信。我们在不同的线程中实现了不同的操作(如数据包处理packet processing、结果报告result reporting和周期同步epoch synchronization),并将它们封装成一个可以插入任何平台的库(如OVS-DPDK[54]和PktGen[58])。
Switch. 我们在P4中实现交换机操作[56],并将嵌入式字段放在以太网和IP头之间。我们支持每台交换机和每台端口的部署;在每台端口的部署中,每个端口都可以看作是一台逻辑交换机。我们为所有的slots分配一个区域的寄存器,这样一个数据包可以根据它嵌入的交换机索引、epoch和交换机端口(在每个端口部署中)来定位它在一个区域中的slots。为了实现高效的slot,我们预先计算一些依赖性操作(如modulo、left-shift和add)的部分结果,并将它们存储在匹配动作表中(match-action tables)。对于每个数据包,我们对部分结果进行查表,并以ALU计算最终结果。
Controller.我们分别用mTCP[31]和ZeroMQ[77]将控制器连接到每个终端主机和交换机。控制器通过多线程进行并行操作。它用特征库(eigen library)[19]求解线性系统(§5)。
Query engine. 为了支持富于表现力的(expressive)网络遥测,我们实现了一个基于Sonata[24]的基本查询引擎。具体来说,查询引擎把Sonata中类似SQL的表达式应用到遥测任务上。然后调用Sonata的编译器将任务翻译成不同的运算符。它从运算符( operators)中提取相关的流键( flowkeys)和统计数据(statistics )。最后,它为OmniMon生成一个特定的配置( configuration),该配置仅监控提取的流键和统计数据。
8. EVALUATION
我们进行测试平台实验,将OmniMon与11种最先进的遥测设计在各方面进行比较。我们总结了我们对OmniMon的发现:
- 它比基于终端主机的遥测系统:Trumpet[49]实现了更高的吞吐量(Exp#1)。
- 它比四种sketch方案(其误差非零)[ SketchLearn29,FlowRadar38,UnivMon43,Elastic Sketch72]消耗更少的开关资源使用量,同时实现零误差(Exp#2)。
- 即使流量是$10^6$数量级,它也能在有限的时间内完成控制器的操作(Exp#3)。
- 与网络遥测的同步解决方案Speedlight[73](Exp#4)相比,它所产生的交换机资源使用量更少,时间边界偏差更小。
- 在极端情况下,它推断出99.7%的数据包丢失(Exp#5)。
- 与SwitchPointer[67]相比,它消耗的资源使用量要少得多,同时实现了更好的可扩展性(scalability),即使当流的数量增加到$10^6$时也是如此(Exp#6)。
- 它支持11种异常检测应用,其中它产生的开销比Marple[52]和Sonata[24]要少,同时实现零错误(Exp#7)。
在附录中,我们通过模拟大规模部署进一步评估OmniMon。它在四种类型的数据包丢失中实现了完美的诊断,并优于另一个诊断系统007[4](Exp#8)。它支持负载均衡算法的性能评估,并且比HashPipe[65]更准确地定位每条链路的顶级流量(top flows)(Exp#9)。最后,我们在Exp#2中展示提了交换机资源使用情况的明细,在Exp#7展示了每个应用的资源-精度权衡(resource-accuracy trade-off)。
8.1 Setup
Testbed.(试验台)我们在8台服务器和3台Barefoot Tofino交换机中部署了我们的OmniMon原型[70]。每台服务器都有两个12核2.2GHz的CPU,32GB内存和一个双端口40Gbps的网卡,而每台交换机有32个100Gb端口。我们在每台服务器中部署一台终端主机,并将控制器与一台终端主机服务器共同部署。我们部署两台交换机作为边缘交换机,每台交换机由四台服务器连接,其余交换机作为核心交换机,由两台边缘交换机连接。
Workloads.(工作量)我们在CAIDA 2018[11]中选取了一个小时的追踪( trace)。为了模拟数据中心流量的局部性,我们将跟踪(trace)中的IP地址映射到我们的终端主机,并生成一个工作负(workload),其中85%的流量是边缘局部的( edge-local),正如[60]中所报告的那样。我们使用不同的epoch长度,使每个终端主机的活动流量(active flows)的范围都是$10^3$到$10^6$(比实地研究[2,60]中的报告多得多)。我们使用PktGen[58]在终端主机中生成跟踪工作负载(trace workloads)。为了消除磁盘I/O开销,每个终端主机将traces(修改了IP地址)加载到PktGen的内存缓冲区,并尽可能快地发出流量,以对我们的原型进行压力测试。
Methodology.OmniMon对每个流进行九种类型的统计计数:数据包计数、字节计数、SYN计数、FIN/RST计数、SYN-ACK计数、ACK计数、40字节的数据包计数、带有特殊字符串的数据包数量(如’zorro’)以及每个流最新的epoch(packet counts, byte counts, SYN counts, FIN/RST counts, SYN-ACK counts, ACK counts, 40-byte packet counts, number of packets with special strings (e.g., ‘‘zorro’’), and the latest epoch of a flow.)。每台交换机部署四组slots。每组有3,072个slots,用于一个纪epoch,并在一个epoch结束时收回以重复利用。 我们将每个流程映射到𝑑=2个slots(§6)。因此,每个epoch有$\left(\begin{array}{c}3072 \\2\end{array}\right) \approx 4.7 \times 10^{6}$个流量映射,足以容纳所有的活动流量。(注意,一个流量同时出现在源端主机和目的端主机中,所以假设8个端主机中每个端主机最多有$10^6$个活动流量,网络中最多有$4×10^6$个活动流量)。每张图显示了100次运行的平均结果,并省略了误差条(error bars),因为它们可以忽略不计。
8.2 Results
(Exp#1) End-host overhead.我们首先通过比较OmniMon和Trumpet[49](一种基于零错误的终端主机遥测系统)来评估终端主机的开销。需要注意的是,Trumpet只针对终端主机设计,而OmniMon也提供交换机端信息。开源的Trumpet原型(称为’’Trumpet-Full (TF)’’)实现了针对不同网络事件匹配的4096个 triggers 。我们还实现了一个简化的变体(称为’’Trumpet-Simple (TS)’’),该变体使用一个单一的触发器( trigger )来跟踪与OmniMon相同的九个流量统计数据,以便进行公平比较。图6(a)显示了OmniMon(OM)、两种Trumpet变体的吞吐量,以及在单个CPU核上使用PktGen生成数据包的情况。TF只实现了6.5Mpps,因为它对4,096个触发器( triggers)执行匹配。TS比TF快,但由于事件匹配开销,比OmniMon慢。与 PktGen 相比,OmniMon 的吞吐量仅有 5.4% 的轻微下降($10^6$ 个流量)。图6(b)显示了OmniMon中每个数据包处理的CPU周期数的明细。吞吐量的下降主要来自于每个数据包的哈希查找。
(Exp#2) Switch resource usage.我们将OmniMon在交换机资源使用方面与四种sketch解决方案进行比较。FlowRadar(FR)[38]、UnivMon(UM)[43]、ElasticSketch(ES)[72]和SketchLearn(SL)[29]。所有sketch解决方案都使用紧凑的数据结构进行近似测量,以适应有限的交换机内存。我们根据他们在P4中发布的设计,在我们的交换机中重新构建它们来测量每流数据包计数。为了进行公平的比较,我们建立了一个简化的OmniMon(OS),它只测量每个流量的数据包计数。我们将所有解决方案与我们的完整OmniMon版本(OF)进行比较,该版本跟踪9个流量统计。
图7描述了交换机资源的使用情况,在内存使用情况、阶段(stages)和动作(actions)的数量(衡量计算资源),以及包头向量(PHV)大小(衡量跨阶段(stages)传递的消息大小)。FR和UM都维护了额外的数据结构(如bloom过滤器和堆heaps)来进行流密钥(flowkey)恢复,因此会产生很高的内存使用率(图7(a))。此外,sketch解决方案还执行多个哈希计算,触发(trigger)许多阶段(stages)和动作(actions)(图7(b)和7(c))。ES和SL更新计数器的不同部分,并产生很大的PHV(图7(d))。对于OmniMon来说,OS是资源高效的,因为它的协作设计只在交换机中施加值更新;即使对于测量更多统计数据的OF来说,它的交换机资源使用量也与sketch解决方案相当。请注意,OmniMon实现了完全的精确性,但sketch解决方案却不能。
(Exp#3) Controller overhead.我们评估了测试平台中流映射、epoch同步和集体分析的控制器开销。回顾一下,我们在不同的线程中运行这些操作(§7)。在这里,我们将每个线程配置为在单个CPU核中运行。图8(a)显示,epoch同步可以在20 𝜇s内完成,这对epoch边界偏差( epoch boundary deviations)至关重要。流程映射(Flow mapping)需要更多的时间,但它只在启动时调用。最昂贵的操作是集体分析,其$10^6$个流的完成时间为180毫秒。我们发现其主要开销来自于对线性系统(linear system)的求解。然而,我们可以通过更多的CPU核来加快计算速度[50,66]。图8(b)通过比较有这些操作和没有这些操作的终端主机的吞吐量,显示了这些操作对终端主机的影响。所有的操作都显示出有限的吞吐量下降,因为我们将它们与数据包处理隔离在不同的线程中(§7)。
(Exp#4) Consistency.我们通过比较OmniMon和开放源码的Speedlight(SPL)原型[73](一种网络遥测的同步解决方案)来评估epoch同步。我们将用P4 BMv2[55]编写的SPL原型改编到Tofino交换机上。图9(a)显示了交换机资源的使用情况,与完整的OmniMon版本的资源使用情况进行了标准化。SPL实现了Chandy-Lamport算法[13],开销很大,而OmniMon由于其外延同步是由终端主机和控制器完成的,所以资源效率更高。
我们研究当本地时钟松散同步(loosely synchronized)时,每个epoch边界的时间偏差(time deviations)。我们在每台服务器中部署了多个(最多1,024个)终端主机实例。我们将终端主机的本地时钟调整为相差1毫秒。图9(b)显示,由于SPL只依靠带内数据包进行同步,因此SPL受到很大的偏差(几乎到了时钟差1毫秒)。如果流量没有跨越所有的终端主机,一些终端主机仍处于旧的epoch。OmniMon将偏差限制在60 𝜇s,即使是1,024个终端主机,因为它利用控制器来约束偏差,并使用mTCP来绕过内核空间(§7)。
我们在straggler case情况下进一步评估了epoch同步精度。我们配置一个straggler终端主机,其本地时钟与其他主机的时钟相差范围是1毫秒到1秒。图9(c)测量了该杂散型(straggler)终端主机中每流数据包计数的平均相对误差。对于SPL,当差值为100毫秒和1秒时,误差分别增加到26%和33%,因为epoch边界偏差(epoch boundary deviation)将许多数据包映射到一个错误的epoch。OmniMon保留了零误差,因为它将所有终端主机和交换机的每个数据包都包含在相同的epoch中。OmniMon保留了零错误,因为它在所有终端主机和交换机的同一时间段内包含了每个数据包。图9(d)测量了流量完成时间的平均相对误差。我们专注于超过1 s的长寿命流量(这通常意味着重要的网络事件[14])。虽然OmniMon以epoch为单位测量粗粒度的时间戳(§6),但其误差只有0.7%,因为它约束了epoch边界偏差。对于SPL来说,当时钟偏差为1 s时,误差在22%以上。
(Exp#5) Accountability.我们的默认设置提供了足够的slots来为每个流分配唯一的流映射。在这里,我们考虑一种极端的情况,其中每个交换机使用512个slots(即$\left(\begin{array}{c}512 \\2\end{array}\right) \approx$130K流映射)。我们将epoch长度设置为两分钟,以使一个当前epoch平均有380K个并发流。我们还将丢包率设置为0.5%。我们将OmniMon与两个变体进行比较:(i)“ Oracle”,它预先知道所有有损流,并将最小slot重叠的有损流量映射为具有最大矩阵等级;(ii)“Random”,它会为每个流程随机选择一个slot。图10(a)显示了这三个方案(一个原型,两个变形)的每次调用的CPU周期数。OmniMon和Random消耗少于一个CPU周期,而Oracle要求每个数据包超过300个周期才能获得最大等级映射。
我们还评估了可以通过§5.2中的四个步骤求解的每个交换机、每个流包丢失变量的分数。对于这三种方案中的每一种,我们使用步骤1和2建立线性系统,并考虑两种变体。(i)’’w/o DCN’’,其中我们跳过步骤3,直接求解线性系统;(ii)’’w/ DCN’’,其中我们执行步骤3,简化了具有数据中心网络特性的线性系统。图10(b)显示,如果不执行Step 3,所有方案只能推断出50%左右的变量,因为损耗流的数量(即𝑛)超过了可用slots的总数(即每个交换机512个)。通过对步骤3的简化,Oracle推断出所有变量,而OmniMon推断出99.7%的变量。在这里,OmniMon不能实现100%的推断,因为我们考虑的是一种极端情况,然而在实际情况下,完全的准确性是可以实现的(附录中的Exp#8)。
(Exp#6) Scalability. 我们将OmniMon与开源的SwitchPointer原型[67] (SP)在可扩展性方面进行比较。我们将用P4 BMv2编写的SP原型改编到Tofino交换机上。图11(a)显示了与OmniMon相同的交换机资源使用情况。SP专注于网络内的可见性,而资源与精度的权衡不是它的重点。它在完美散列的情况下实现了零错误,但对于复杂的计算,会产生较高的交换机资源开销。请注意,完美散列( perfect hashing)需要先验地获取所有可能的流密钥来设计完美的散列函数。这对于 IP 地址是可行的,但对于 5 元组( 5-tuples)(最多$2^104$个流量)则不可行。图11(b)比较了零错误保证所需的内存使用情况。SP的内存使用量随着流密钥的数量线性增长,因为每个slot都与一个流相关联,而OmniMon的内存使用量增长速度要慢得多,因为𝐾槽位可以容纳$\left(\begin{array}{l}K \\d\end{array}\right)$流(§5.2)。
(Exp#7) End-to-end performance comparison.我们将OmniMon与Sonata[24]和Marple[52]的交换机控制器架构进行比较。我们的端到端性能比较针对Sonata[24]报告的11个异常检测应用。比较内容包括三个方面:(i)每台交换机资源使用量;(ii)每台交换机发送到控制器的流量;(iii)每个应用的检测精度。由于Sonata和Marple在设计中不涉及终端主机开销,因此我们不比较终端主机开销。如Exp#1和Exp#3所示,OmniMon的终端主机开销有限。
OmniMon跟踪九种流量统计以支持11种应用。对于Sonata,如在§2.2中,我们同时考虑’’Sonata-FA(S-FA)’’ (with full accuracy)和’’Sonata-AD (S-AD)’’ (with accuracy drop),其中每个交换机端操作符都配置了$2^{16}$计数器,就像其开源原型一样。对于Marple,我们实现了它的键值缓存,并删除旧键来处理哈希碰撞。我们和Marple[52]一样配置了$2^{16}$个缓存slots。对于OmniMon,我们采用了包括所有9个统计数据的完整配置(’’OM-F’’)。我们还采用了基于Sonata的查询引擎(§7)来为每个应用生成配置(‘’OM-Q’’)。我们在每个epoch设置了$10^5$个流量。由于Sonata、Marple和OM-Q各自部署了每个应用,我们对11个应用的结果进行平均。(每个应用的结果见附录)。
图12(a)比较了每个交换机的资源使用情况,与OM-F的资源使用情况进行了标准化。Sonata-AD牺牲了准确性,消耗的内存、阶段(stages)和动作(actions)最少。Sonata-FA和Marple需要更多的资源用于流键跟踪和缓存驱逐(flowkey tracking and cache eviction)。OM-F由于其集体分析(§3.2),在跟踪所有9个统计数据的同时,交换机内存使用量比Sonata-FA和Marple都少。它对其他三类资源的使用量与Sonata-FA和Marple中的单个应用部署相当,因为它只在交换机中执行(简单的)值更新操作。有了查询引擎,OM-Q的资源使用量进一步下降。
图12(b)比较了发送到控制平面的每个交换机的流量。Sonata-FA和Marple通过将冲突的流量驱逐到控制器来保持准确度,但由于当流量很大的时候经常发生哈希碰撞,因此会引发大量流量。Sonata-AD将每个交换机、每个应用的流量降低到5 MB/s,但会带来精度下降。相比之下,OM-F触发了180 KB/s的流量,但没有精度下降。查询引擎进一步减少了流量(26 KB/s),因为它只跟踪每个应用感兴趣的统计数据。
图12(c)比较了由F1分数量化的检测精度。Sonata-AD的F1分数只有74%左右,因为它没有在数据平面上解决哈希碰撞以提高资源效率。Marple和Sonata-FA提高了准确性,但在交换机和控制器中产生了高资源开销。OmniMon既能实现资源效率,又能实现完全的准确性。why? 如何既不产生高资源开销,又能实现完全的准确性
9. RELATED WORK
Resource-accuracy trade-off. 现有的网络遥测建议往往是在资源与精度之间进行权衡。基于终端主机的遥测系统[1,49]可以执行完整的每一个流量跟踪,但在整个网络范围内的可见性有限,并且会产生过多的内存占用。基于交换机的方法要么放宽精度[47],要么限制于特定的查询[51]。近似算法[5,26,28,29,38,43,48,62,63,65,72,75]以精度换取资源效率。有些系统以尽最大努力的方式[59]或根据预先定义的流量模式[25,52,69,74,76,79]将流量镜像到控制器,但不可避免地错过了没有镜像的流量。
最近的混合架构结合了不同的实体进行网络遥测[24,32,42,52,67]。为了减轻资源负担,它们依靠采样[42]和/或事件匹配[24,42,52,67]来只关注感兴趣的流量,因此无法实现完全准确。此外,它们没有解决实体协调中的一致性和问责制问题(consistency and accountability)。
Consistency. (一致性)HUYGENS[21]提出了软件时钟同步,但其机器学习的设计在交换机部署中比较复杂。 Swing State[44]通过状态迁移确保数据平面状态的一致性,但带来沉重的状态更新成本。Synchronized Network Snapshot[73]实现了P4交换机的因果一致性(弱一致性weak consistency的一种形式)。OmniMon实现了混合一致性,并且更加轻量级(§8中的Exp#4)。
Accountability.损失推理(Loss inference)在网络遥测中得到了很好的研究。主动探测(Active probing)[23,68]发送探测包来测量路径损耗,但只覆盖了路径的子集。被动监测( Passive monitoring)分析网络流量,但依赖于领域知识[79]和/或采用近似技术[4,22,39,61]来估计损失率。OmniMon利用终端主机中完整的统计数据作为基础真相(ground truth),形成一个线性系统进行精确的丢包推理(packet loss inference)。
10. CONCLUSION
OmniMon是一种针对大型数据中心的网络遥测架构。它的设计原则是重新架构全网协作,精心协调所有实体之间的遥测操作。我们展示了OmniMon如何在保证一致性和责任性(consistency and accountability)的前提下,实现资源效率和完全的准确性(resource efficiency and full accuracy)。实验表明OmniMon在11个最先进的遥测设计上的有效性;更多结果见附录。
补充:
- 布谷鸟哈希:Cuckoo hashing
- 数据中心
- QDISC排队规则
- CAIDA: Center for Applied Internet Data Analysis
- 9 flow statistics和11 applications之间的关系
- slot是硬件还是软件?cache slots
- 流映射?